
The Challenge - The sinking of the Titanic is one of the most infamous shipwrecks in history. On April 15, 1912, during her maiden voyage, the widely considered “unsinkable” RMS Titanic sank after colliding with an iceberg. Unfortunately, there weren’t enough lifeboats for everyone onboard, resulting in the death of 1502 out of 2224 passengers and crew. While there was some element of luck involved in surviving, it seems some groups of people were more likely to survive than others. In this challenge, we ask you to build a predictive model that answers the question: “what sorts of people were more likely to survive?” using passenger data (ie name, age, gender, socio-economic class, etc).
reference - Kaggle.com
Go to Kaggle CompetitionStep 1
List all the files present in the directory, to verify if all the 3 files - train.csv, test.csv and gender_submissions.csv are present
Step 2
Load Training Data
Step 3
Load Testing Data
Step 4
Let's analyse features.
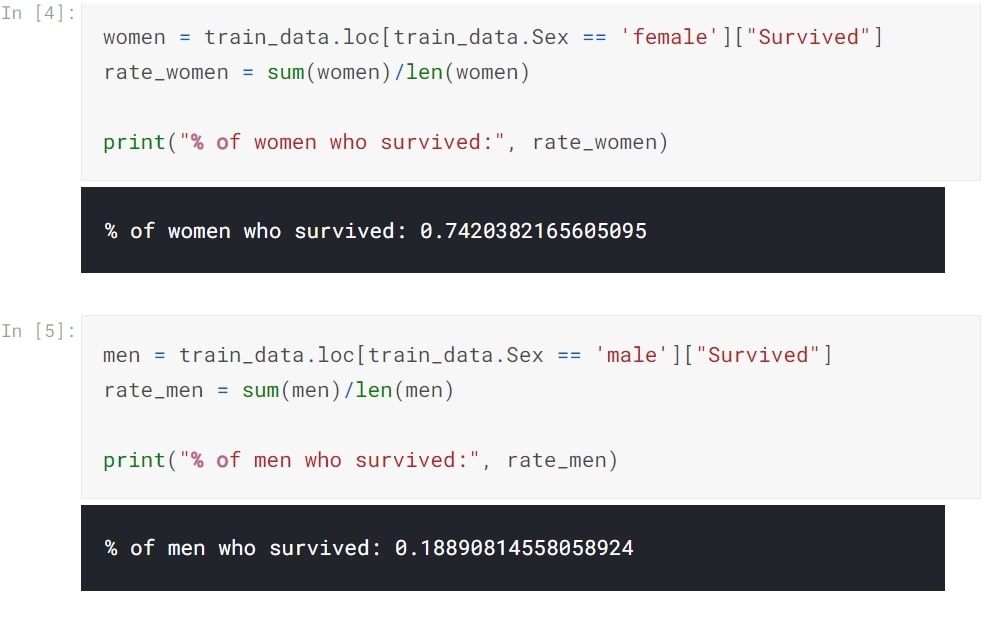
We start with gender based survival ratio. Women clearly show high survival rate.
Step 5
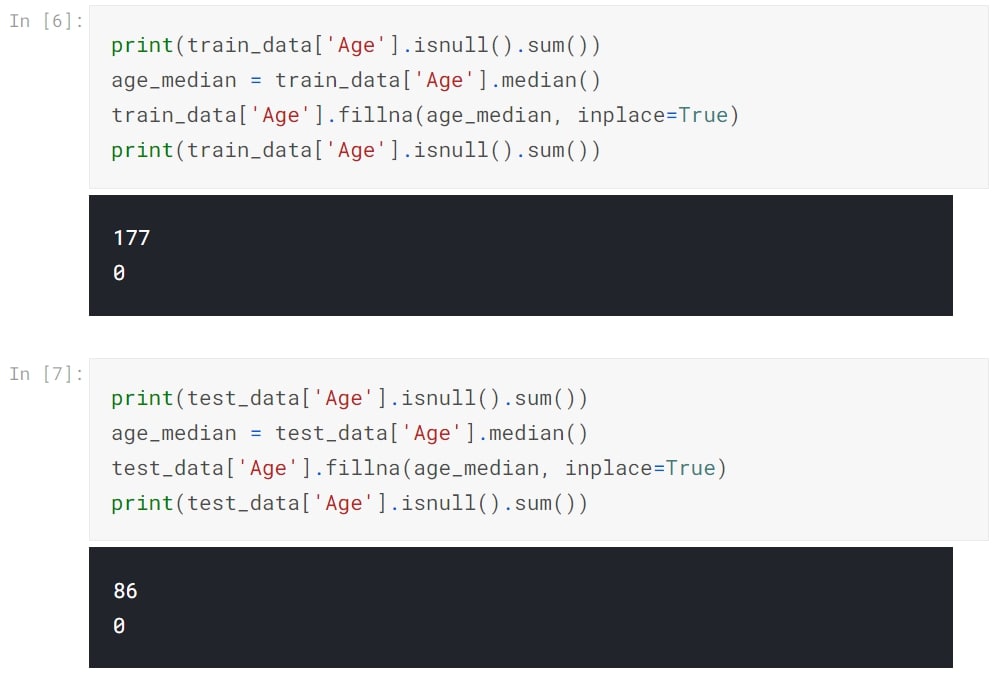
Fill Null Values.
Age feature has null values. We want to use this feature,so we replace all the missing values with a median age.
Step 6
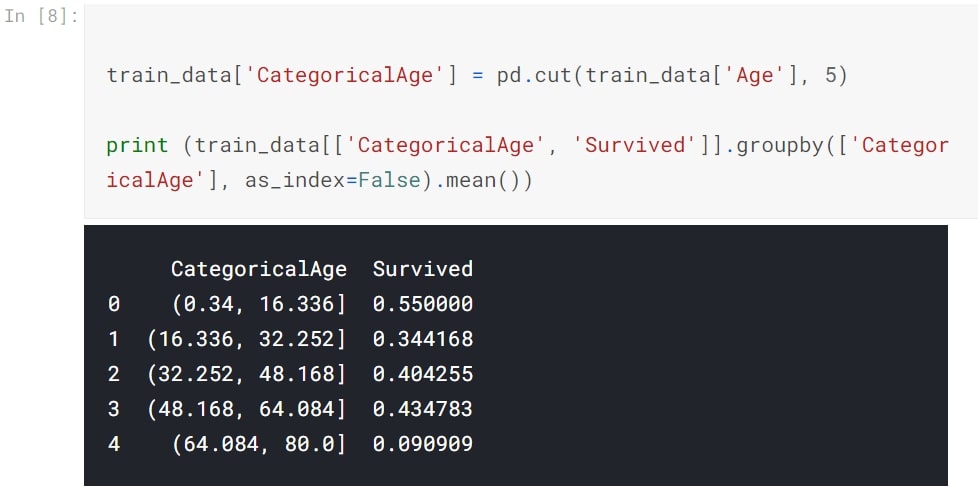
Categorical Age
Divide the Age feature into 5 distinct categories and calculate its survival rate. Categorical data will help us understand people from which age groups have high survival chance.
Step 7
Assign a numeric value to people belonging to different age groups.

Step 8
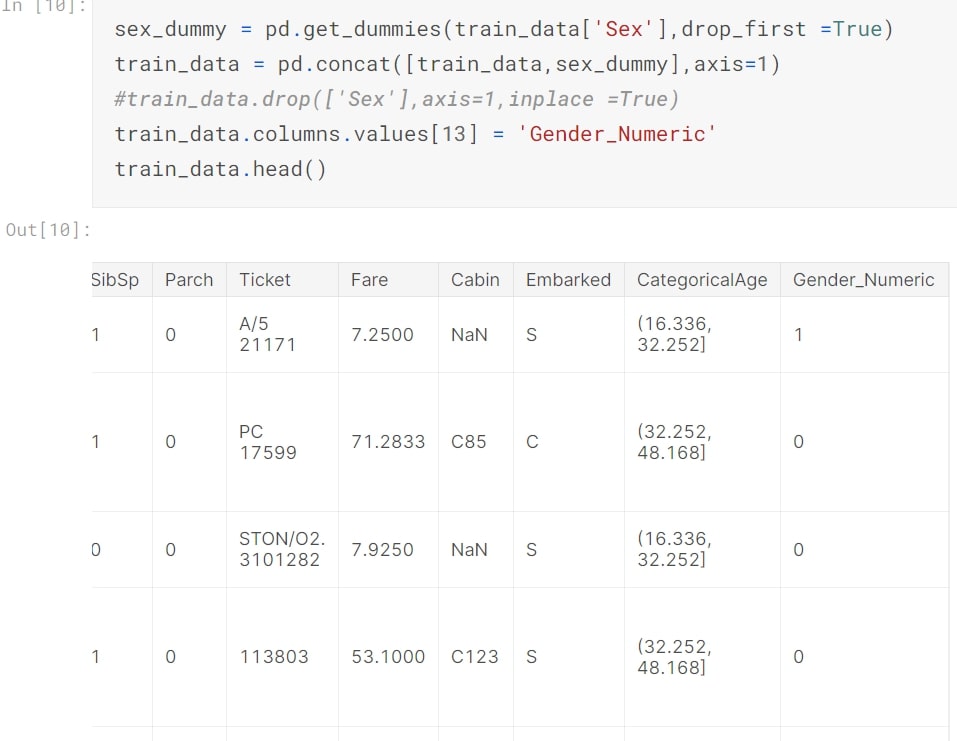
Gender
Convert text values under 'Sex' column into numeric values-'Gender_Numeric' This helps into plotting of the histogram and will be cleaner to use for further processing of data.
Step 9
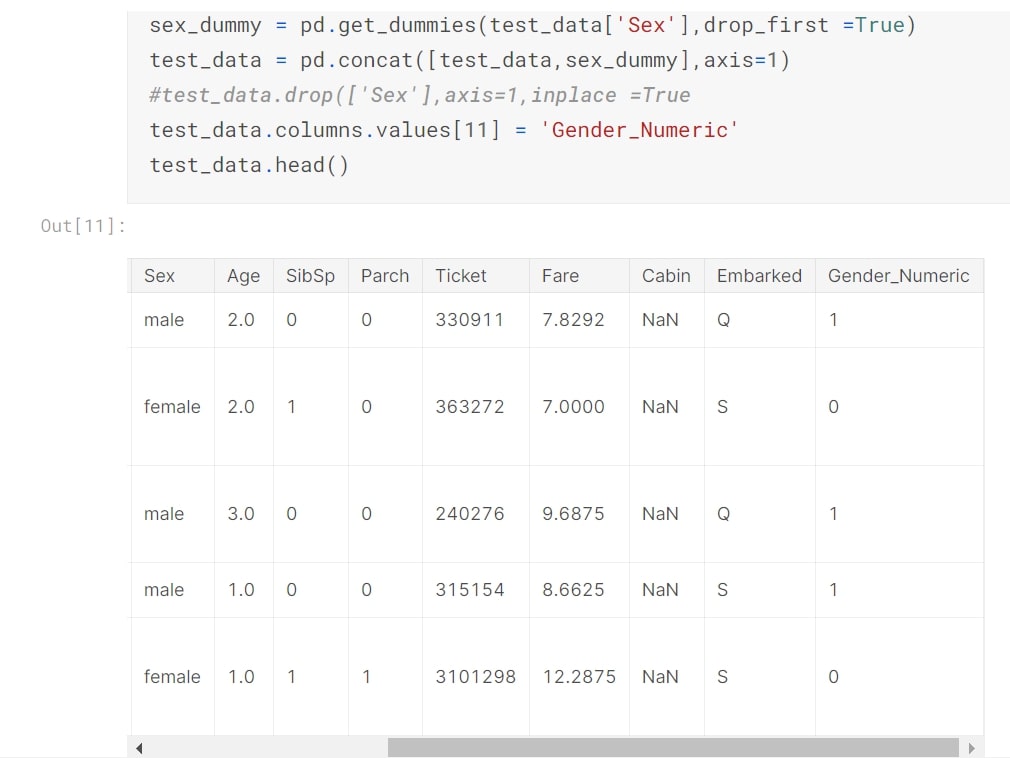
Gender
Repeat for Test Data.
Step 10
Class
There is a higher chance of survival if passengers belong to First Class than Second and Third Class respectively.
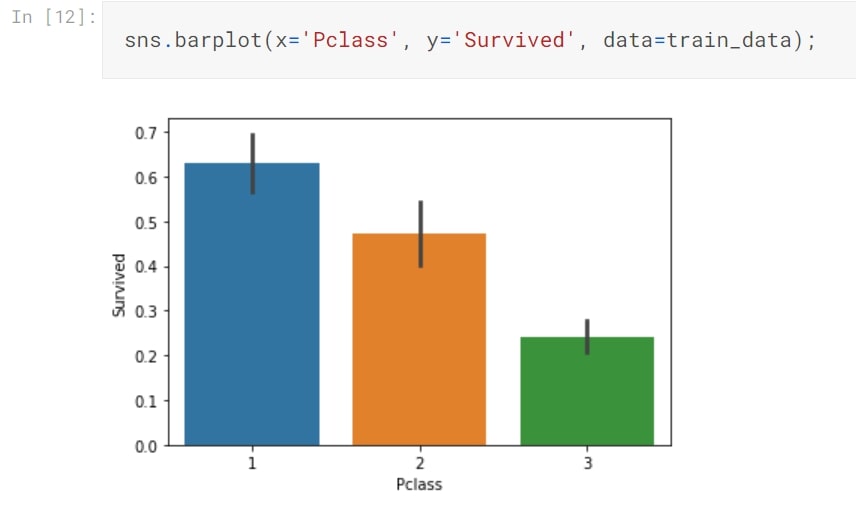
Step 11
Class-Histogram
Plotting a histogram which displays total number of Survived passengers across class.
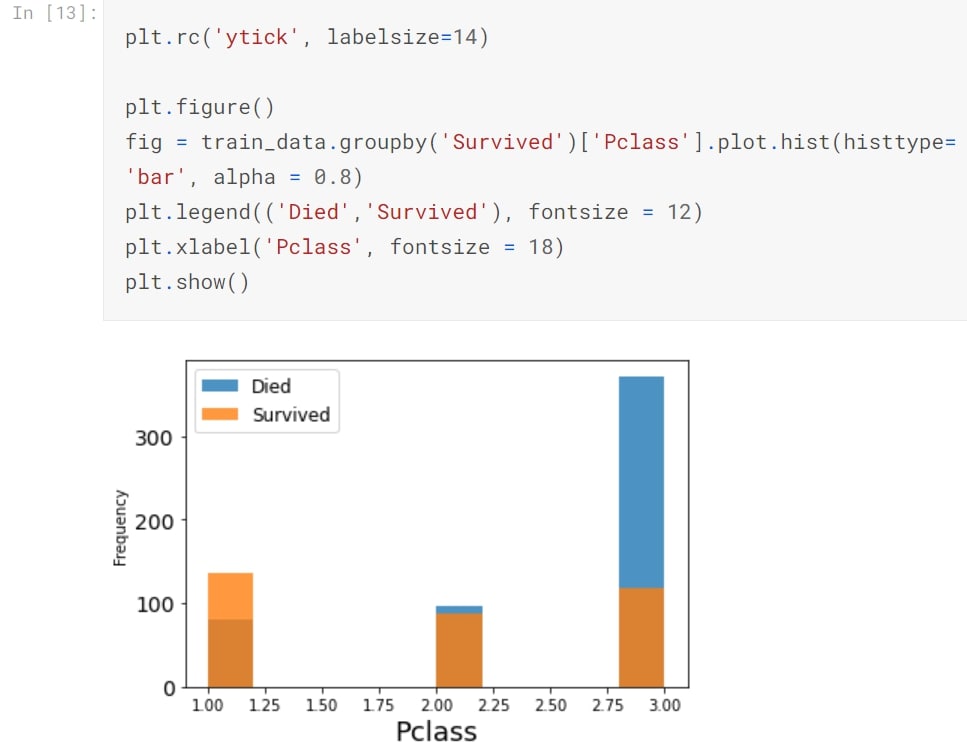
Step 12
Female to Male Survival-Histogram
Plotting a histogram which displays total number of Survived passengers across class.
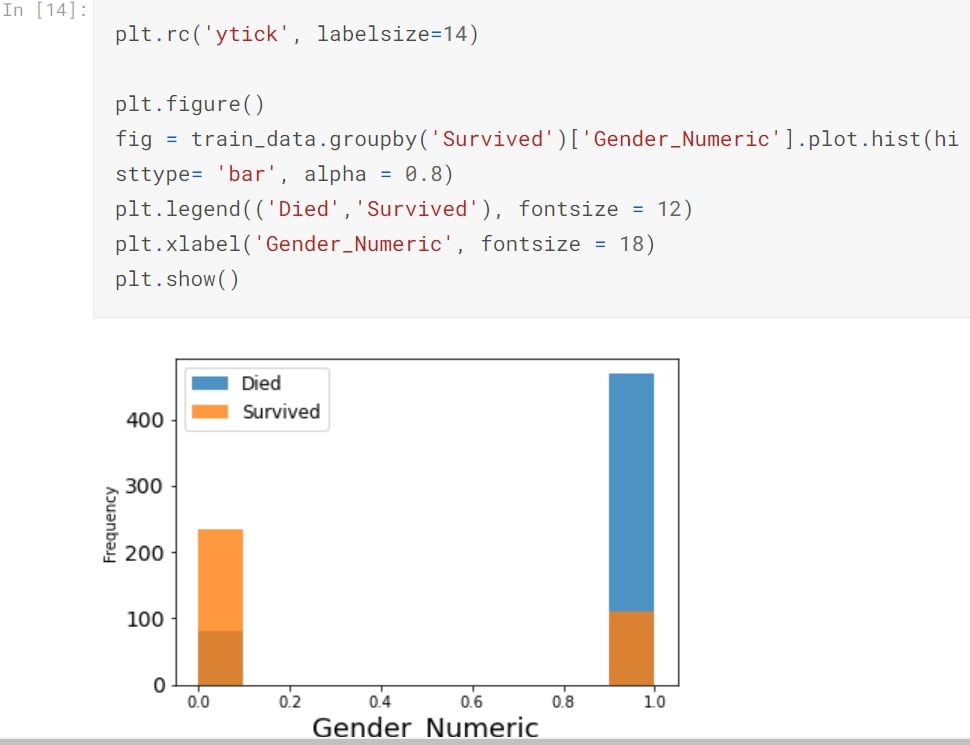
Step 13
Age-Histogram
Now we know that people belong to 5 different age groups and we have assigned a unique numeric value to these groups-
This histogram shows that people belonging to a age group of 16-32 or younger people have higher chance of survival than others.
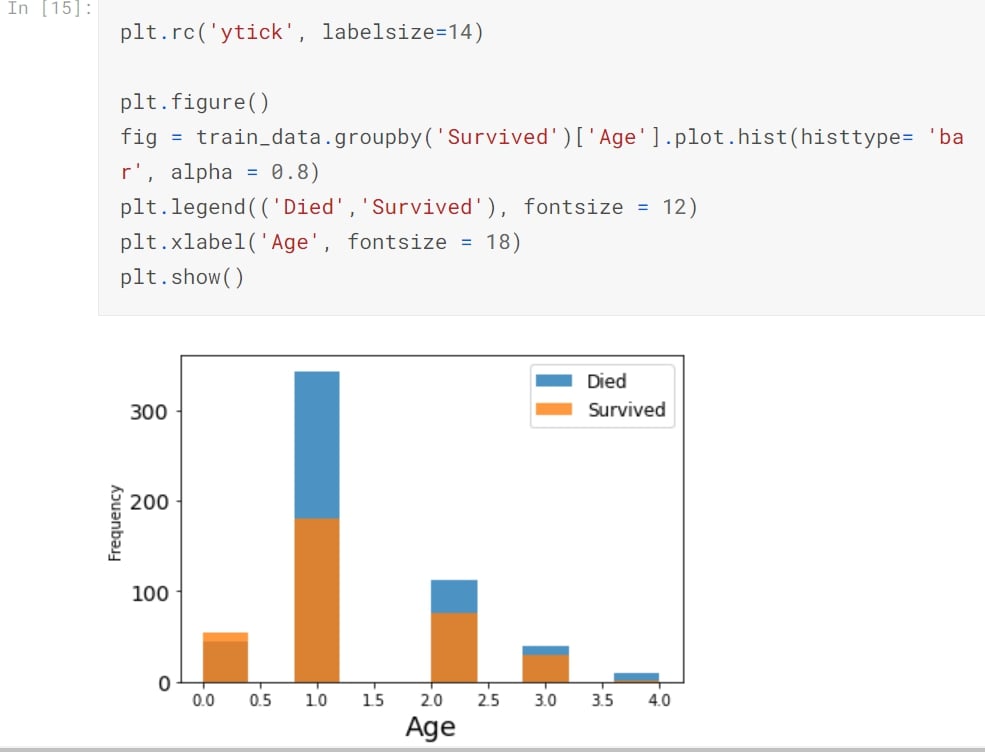
Step 14
Using Random Forest Classifier
We are using Random Forest Classifier to train our model using train.csv and test.csv to predict the survivors.
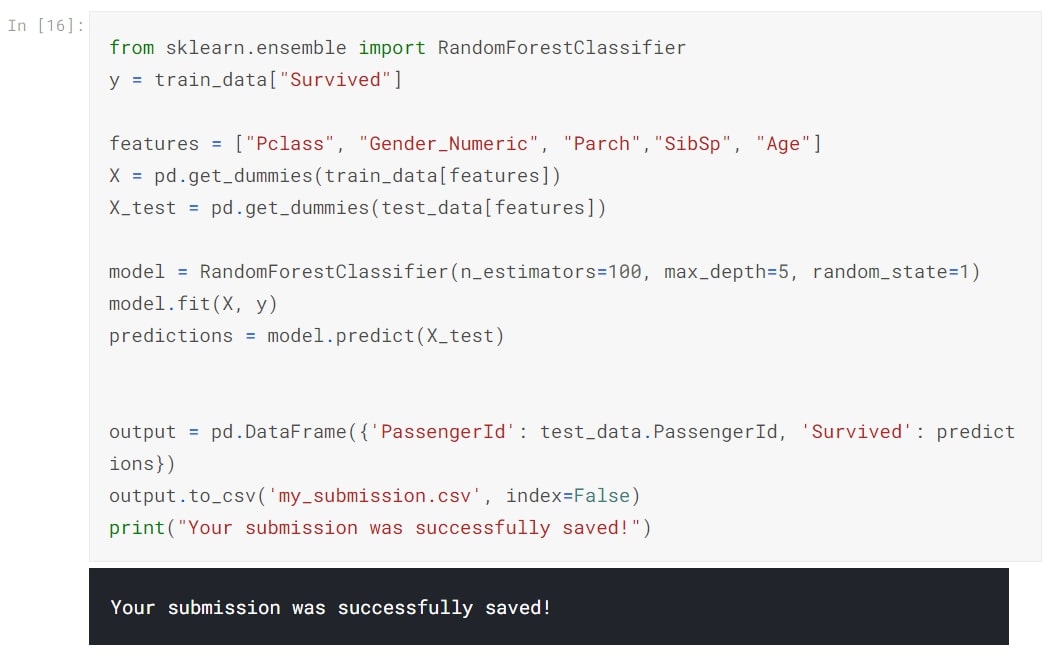
Initial Score
This score was before replacing the Null Values or Categorising Age or Converting text features to Numerical features.
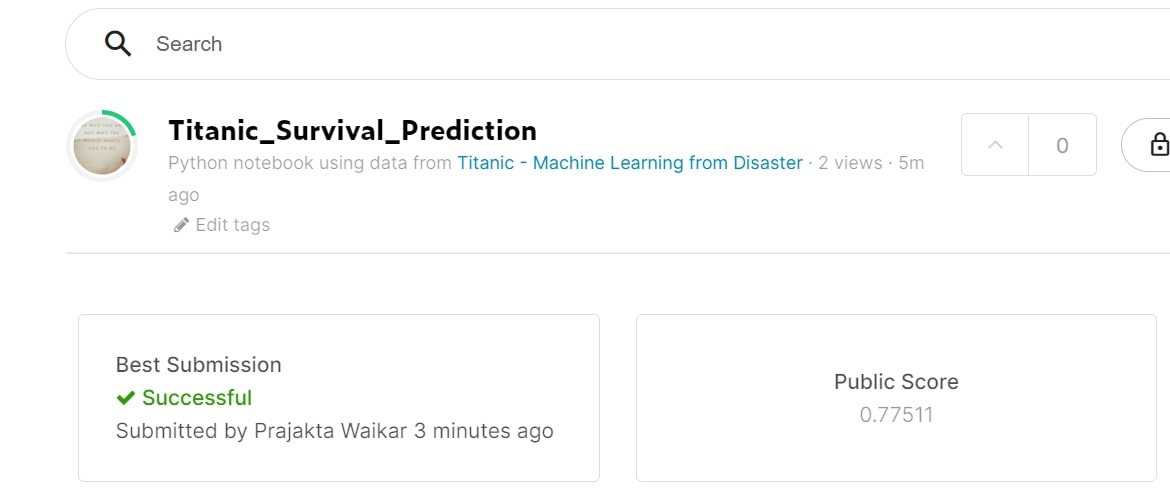
Improved Score
This score was after replacing the Null Values, Categorising Age and Converting text features to Numerical features.
Contributions
Data Visualisation
Data Visualisation helps in understanding the dataset a little more. It helps put words in picture form.We all want data that is easily readable, Data Visualisation helps you do that.Using Histogram to visualize my data which was earlier in a tabular form, helped me streamline which features played an important part into survivor predictions. Based on the histograms above, I decided to keep using Sex, Age and Class as key features
Missing Values
Handling missing values in a large dataset becomes extremely important as not doing so may end up giving us inaccurate inference of data. In this case training and testing both the datasets had large number of missing values for "Age" feature.Dropping rows with null values did not improve my score but rather decreased it.So, I decided to fill thise missing values. I used mean age value and filled it in the missing places. This helped me increase the score a bit.
Categorization
I divided age feature into 5 categories or range. This helped me in grouping the data and visualisation of this feature became easy. After categorising all passengers into age groups, I assigned a numerical value to passengers belonging to a particular group. By doing so, I was able to bring all the desired features in same scale or range.
Text to Numerical
Similar to Age, I also converted text data of Sex feature to numeric, by assigning Male=1 and Female=0. Now all the features are in same scale and level. Applying these data-preprocessing techniques helped in increasing the models accuracy a bit.It also taught what not to do to decrease the accuracy.