
We will use PyTorch to construct a convolutional neural network. We will then train the CNN on the CIFAR-10 data set to be able to classify images from the CIFAR-10 testing set into the ten categories present in the data set.
The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images. The dataset is divided into five training batches and one test batch, each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. The training batches contain the remaining images in random order, but some training batches may contain more images from one class than another. Between them, the training batches contain exactly 5000 images from each class
reference - https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html#sphx-glr-beginner-blitz-cifar10-tutorial-py
CIFAR-10 WebsiteStep 1
Let's take a look at CIFAR-10 dataset classes.
Step 2
Lets import libraries

Step 3
Load Training Data
Convert Python Image Library (PIL) format to PyTorch tensors
Normalize the data by specifying a mean and standard deviation for each of the three channels.This will convert the data from [0,1] to [-1,1]
Normalization helps speed up further conversions


Step 4
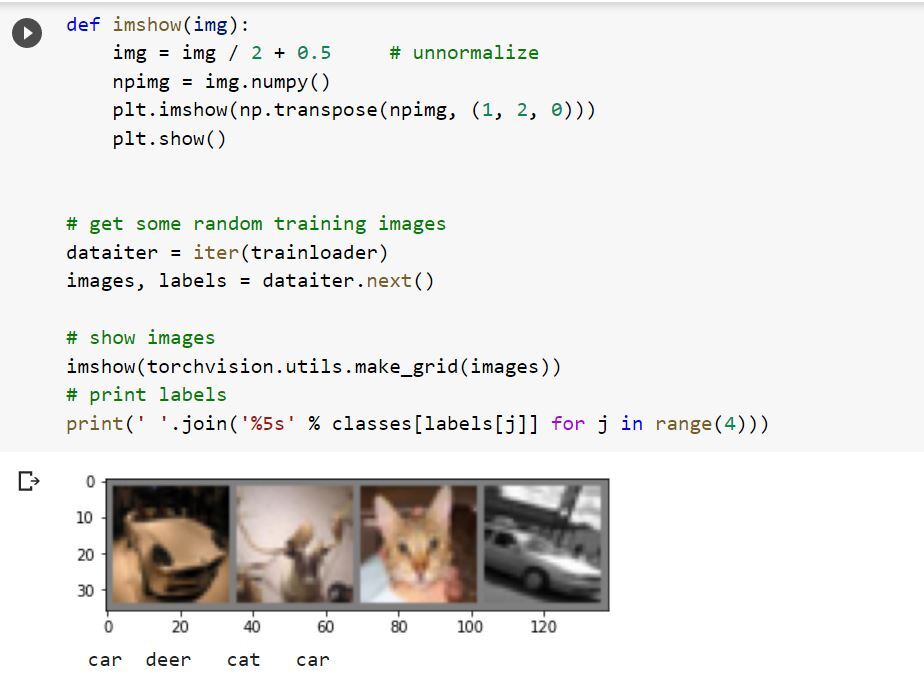
Show some of the training images
Step 5
Define a Convolutional Neural Network.
CNN stands for Convolutional Neural Network which is a specialized neural network for processing data that has an input shape like a 2D matrix like images. CNN’s are typically used for image detection and classification. Images are 2D matrix of pixels on which we run CNN to either recognize the image or to classify the image. Identify if an image is of a human being, or car or just digits on an address.
What is a convolution?
Convolution is a mathematical operation where we have an input I, and an argument, kernel K to produce an output that expresses how the shape of one is modified by another.
CNN
Convolutional Neural Networks take advantage of the fact that the input consists of images and they constrain the architecture in a more sensible way. In particular, unlike a regular Neural Network, the layers of a ConvNet have neurons arranged in 3 dimensions: width, height, depth. For example, the input images in CIFAR-10 are an input volume of activations, and the volume has dimensions 32x32x3 (width, height, depth respectively)
Layers used to build ConvNets
A simple ConvNet is a sequence of layers, and every layer of a ConvNet transforms one volume of activations to another through a differentiable function. We use three main types of layers to build ConvNet architectures: Convolutional Layer, Pooling Layer, and Fully-Connected Layer. We will stack these layers to form a full ConvNet architecture.
- INPUT [32x32x3] will hold the raw pixel values of the image, in this case an image of width 32, height 32, and with three color channels R,G,B.
- CONV layer will compute the output of neurons that are connected to local regions in the input, each computing a dot product between their weights and a small region they are connected to in the input volume. This may result in volume such as [32x32x6] if we decided to use 6 filters.
- RELU layer will apply an elementwise activation function, such as the max(0,x) thresholding at zero. This leaves the size of the volume unchanged ([32x32x6]).
- POOL layer will perform a downsampling operation along the spatial dimensions (width, height), resulting in volume such as [16x16x6].
- The last fully-connected layer uses softmax and is made up of ten nodes, one for each category in CIFAR-10
- Stride actually controls the number of steps that you move the filter over the input image. When the stride is 1, we move the filter one pixel at a time. When we set the stride to 2 or 3 (uncommon), we move the filter 2 or 3 pixels at a time depending on the stride.The value of the stride also controls the size of the output volume generated by the convolutional layer. Bigger the stride, smaller the output volume size.
- Next important parameter is the zero padding. Zero padding refers to padding the input volume with zeros around the border. The zero padding also allows us to control the spatial size of the output volume.
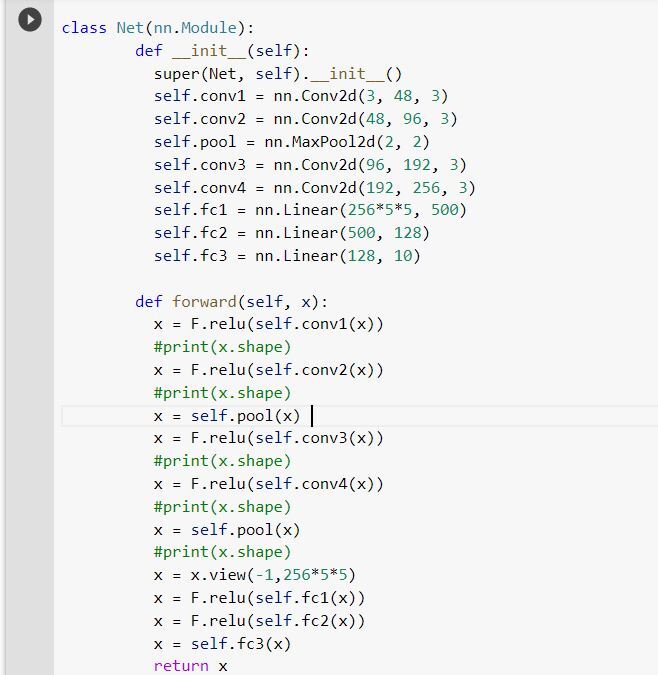
CNN model 1
Number of filters used here are 6, stride is 1 and padding 0.

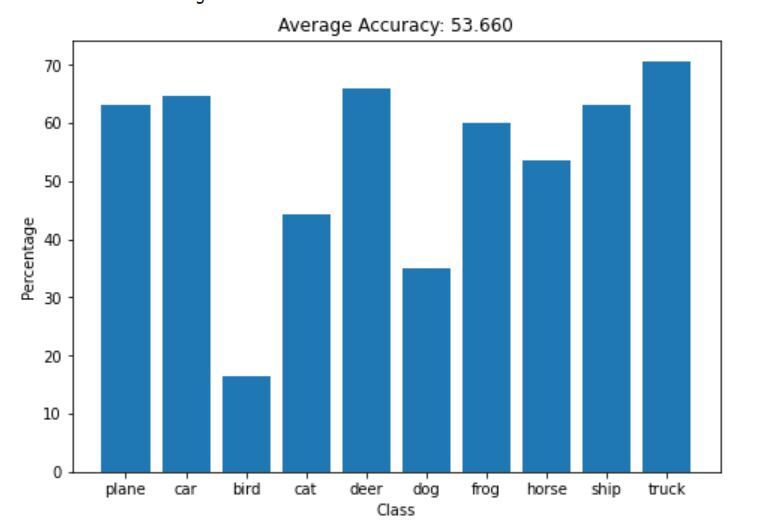
Original Model Accuracy
Following image displays the accuracy of 10000 test images, for 2 epochs.
Let's Improve Accuracy of our model
Increase Epoch from 2 to 10.
One Epoch is when an ENTIRE dataset is passed forward and backward through the neural network only ONCE.
As the number of epochs increases, more number of times the weight are changed in the neural network and the curve goes from underfitting to optimal to overfitting curve.We need to make sure that we are not overshooting the epoch number.For now we will use 10 and observe the losses and accuracy again

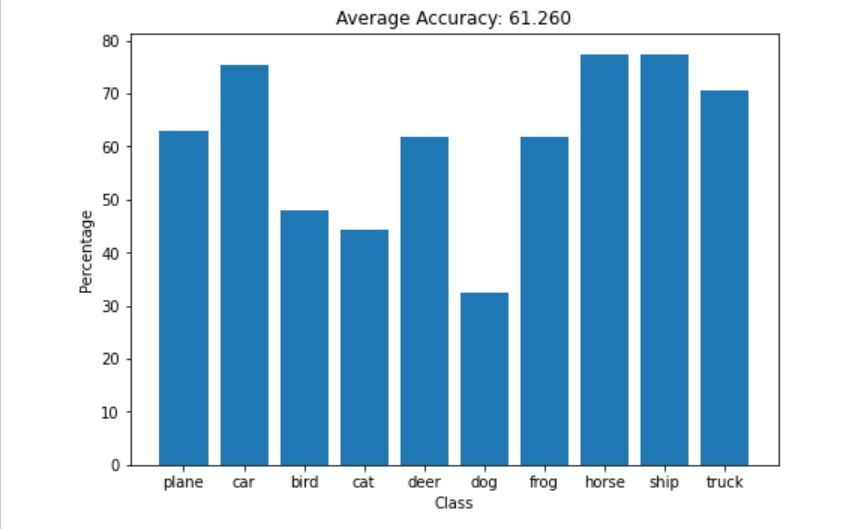
Accuracy for 10 epochs
Just by keeping the model same and increasing the epochs,we were able to train our model better and increase accuracy
Lets increase convolutional ayers from 2 - 4
By Increasing the convolutional layers we increase the complexity of the network, thereby increasing the weights in the network. But one can only try increaing the layers if the dataset is large dataset like CIFAR-10, it will not work if the dataset is very small.
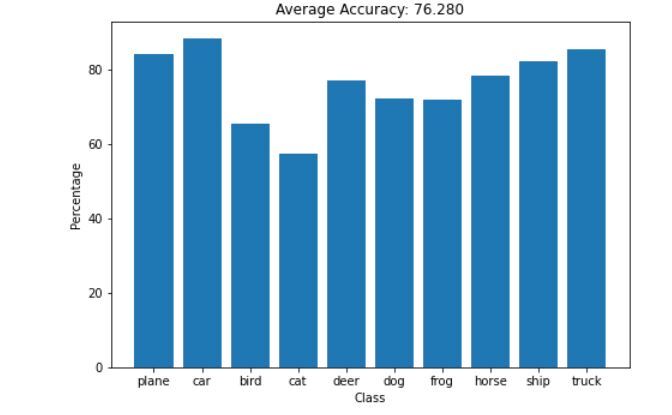
Accuracy for Model 2
Before validating the entire test data set,first lets see if the model is able to predict based on the ground truth on test data
Ground truth

Predicted Classes

Model 2 Accuracy
Now we know that the model is not overfitted, The accuracy has increased after adding 4 convolution layers, 3 filters and more fully connected layers .
Conclusion
The model performed well, achieving an accuracy of 53.6% compared to a baseline of 10%, since there are 10 categories in CIFAR-10, if the model guessed randomly. To improve the performance we can try adding convolution layers, more filters or more fully connected layers. We also train the model for more than two epochs while making sure, not to overfit the training data